


为什么我的RDS 突然变慢了?相信不少客户在使用RDS 中经常遇到的头疼问题。下面我将通过真实案例来分析一下用户在使用RDS 中慢的原因:
案例一:用户从PGSQL迁移到RDS后,发现RDS变慢了。
问题描述:用户的数据库(pgsql)迁移到RDS(mysql)后,发现相同的一条sql 语句,数据量百万级左右,在原来postgreSQL 中执行大概是0.015s,而在RDS 下直接运行是6分20秒左右,执行非常的慢,已经严重的影响了用户使用RDS 使用的信心。
可能原因:为什么在用户的数据库上执行只需要0.015s,而到RDS 后变为了6分20s?根据经验,很有可能是SQL 的执行计划改变了,而导致执行时间剧增。
问题排查:通过explain 查看sql 的执行计划,一步一步进行优化。
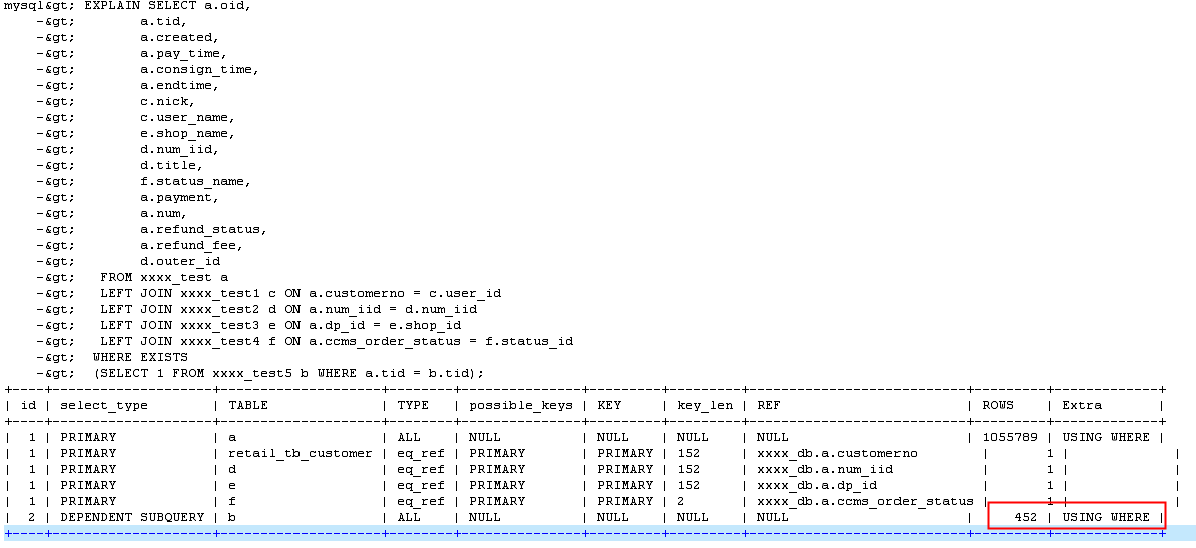
通过分析,我们可以从执行计划上分析b 表做了一个全表扫描(执行计划的最后一行),查看b 表中tid 并无索引,所以我们这里可以进行优化,来减少查询过程中关联的行数,来达到优化:
---------------------------------------------------------------------------------------------------------------------
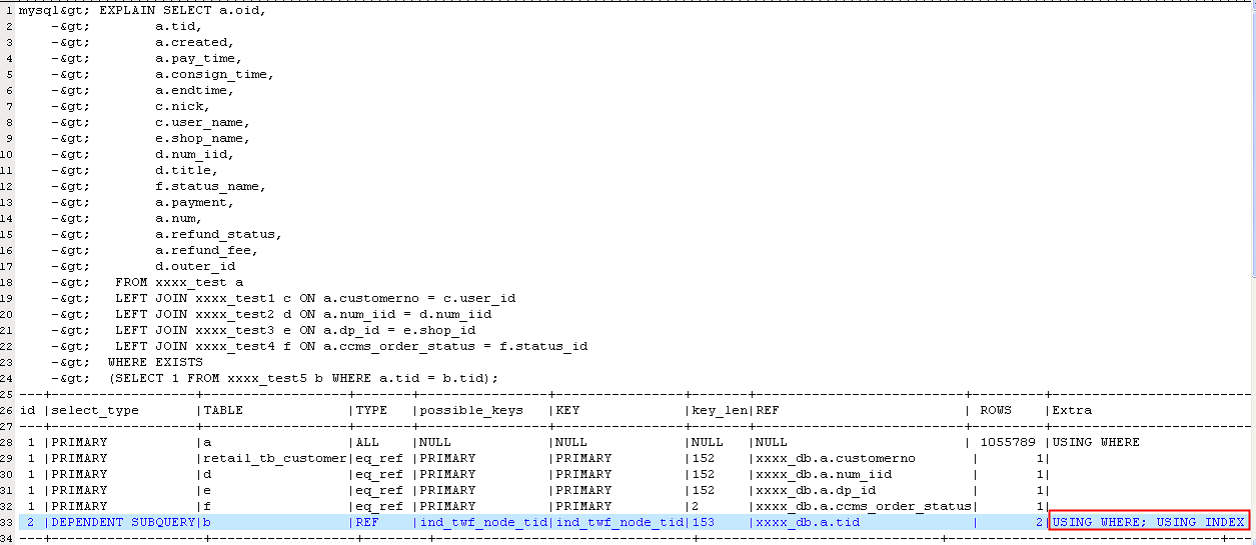
我们可以看到执行计划中的rows 已经从452变为了2(执行计划的最后一行),
由于mysql 表关联只有nest loop join 这种算法,所以我们可以估算一下这里的优化:
原始执行一:1055789*1*1*1*1*452 扫描的行数
新执行计划二:1055789*1*1*1*1*2 扫描的行数
执行时间:
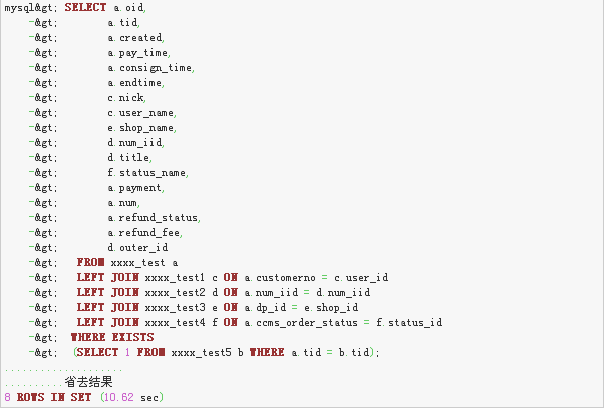
我们看到执行时间已经由原来的6分20秒下降到了10秒,我们继续优化;
可以看到该sql 的结果集只有区区的8行,但是扫描的行数却是非常之大的(1055789*1*1*1*1*2),在优化sql 的非常关键的一点就是优化sql 的执行路程,t=s/v;如果我们能够优化S,那么速度肯定会一下子提上来; 那么我们在看看sql 中最后的一句:
-> WHERE EXISTS
-> (SELECT 1 FROM xxxx_test5 b WHERE a.tid = b.tid);
sql 查询中是要查询出每笔订单的详细信息而不得不关联其他一些表,但是最后的一个exist 限定了我们最后结果的范围,在看看xxxx_test5 这张表有多大:
mysql> SELECT COUNT(*) FROM xxxx_test5;
+----------+
| COUNT(*) |
+----------+
| 403 |
+----------+
1 ROW IN SET (0.00 sec)
mysql> SELECT COUNT(*) FROM xxxx_test5 b ,xxxx_test a WHERE
a.tid = b.tid ;
+----------+
| COUNT(*) |
+----------+
| 8 |
+----------+
1 ROW IN SET (0.42 sec)
两张表关联后只有8行记录,如果我们将订单表xxxx_test 和限定表先做关联,在和其他的一些订单信息表做连接,将会极大减小关联的行数;在进一步改写sql:
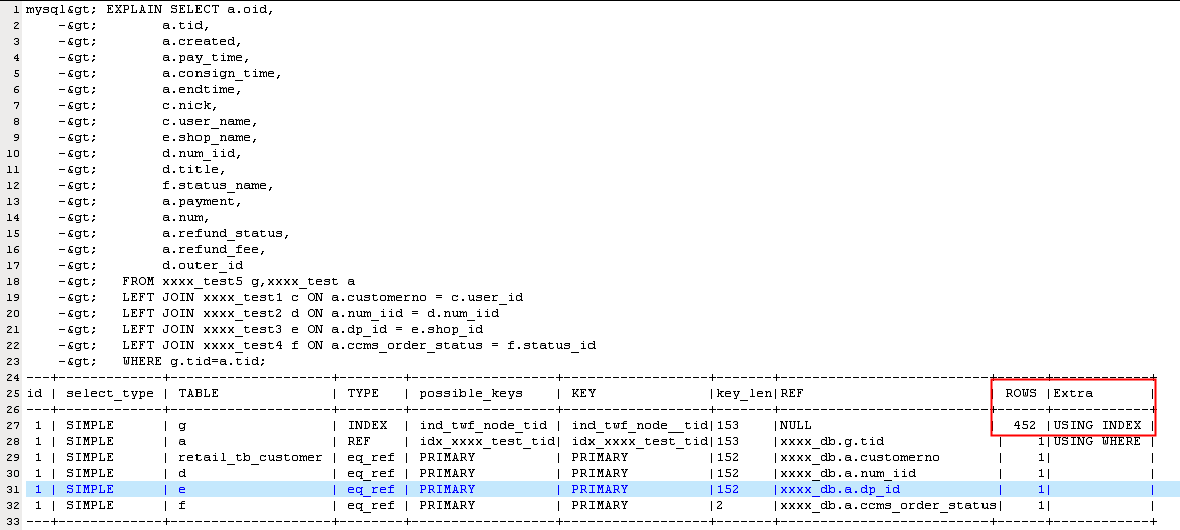
分析执行计划,我们发现限定表xxxx_test5做了驱动表,驱动表的变化才是导致问题的最根本原因,扫描的行数:452*1*1*1*1; 这个时候sql 的执行速度就飞一般感觉了:
Mysql-->;
SELECT a.oi.............
........省去结果
8 ROWS IN SET (0.13 sec)
总结:由于环境迁移,导致sql 执行计划改变,这就是RDS 变慢的最终原因了。
案例二:用户使用RDS(mssql),经常出现连接超时报错
问题描述: 使用mssql rds 时不时报错如下,询问是否是连接超过限制导致的?
A network-related orinstance-specific error occurred while establishing a connection toSQL Server. The server was not found or was not accessible. Verifythat the instance name is correct and that SQL Server is configured toallow remote connections. (provider: SQL Network Interfaces, error:26 – Error Locating Server/Instance Specified)
可能原因:可能用户的应用程序设计不是很好导致数据库锁争用较多;或由于没有建立适当的索引导致全表扫描导致,造成了数据库等待;
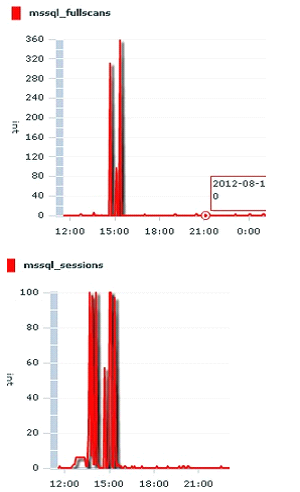
问题排查:通过查看数据库的监控指标,发现在某个时间段有大量的全表扫描,同时数据库的锁争超时,会话数明显增加。
---------------------------------------------------
可以看到在15:00的时候有大量的全表扫描,出现了较多的锁超时的情况,同时这个时候也有大量的会话在数据库中,而这个时间恰好也是用户报出错误的时间,在进一步排查,用户的SQL,通过查看mssql 内部的一些视图,来找到对应消耗资源top 5的sql,发现用户使用频繁的查询一个视图,在视图中有多表连接,但在这些表连接中的字段上没有添加索引,导致了全表扫描,用户视图如下:
CREATE VIEW [dbo].[Vi_xxx]
AS
SELECT ..........
..........
FROM dbo.xxxx_test6 INNER JOIN
dbo.xxxx_test1 ON dbo.xxxx_test5.docID = dbo.xxxx_test1.docID
INNER JOIN
dbo.xxxx_test2 ON dbo.xxxx_test5.typeID = dbo.xxxx_test2.typeID
INNER JOIN
dbo.xxxx_test3 ON dbo.xxxx_test5.docID = dbo.xxxx_test3.docID
INNER JOIN
dbo.xxxx_test4 ON dbo.xxxx_test5.categoryID =
dbo.xxxx_test4.categoryID
WHERE (dbo.xxxx_test5.isDelete = 0)
通过查看执行计划,发现表上面很多的关联字段没有建立索引,导致全表扫描执行计划如下(有很多的table scan):
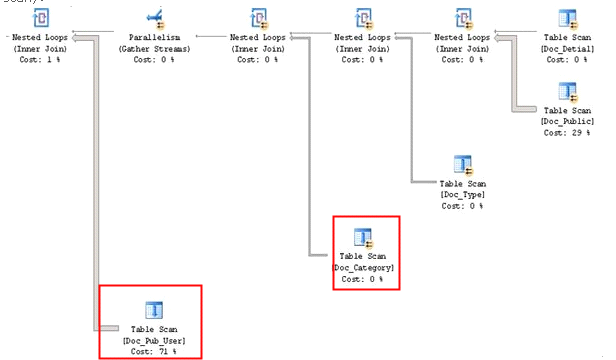
总结:用户频繁的查询一个视图,而该视图中表的关联字段上没有索引,导致了大量的全表扫描,累积了大量的会话数,造成数据库性能的下降,应用与数据库之间出现连接错误。
案例三:隐式转换导致全表扫描
问题描述:用户网站打开缓慢,质疑RDS 性能不好。
可能原因:用户的数据存放在RDS 中,网站访问数据库的时间较长,大多web应用程序设计,SQL没有优化或索引建立的不好导致;
问题排查:通过查看数据库的慢日志,发现大量的慢sql,执行时间超过了2S。
UPDATE USER SET xx=xx+N.N WHERE
account=130000870343 LIMIT 10
SELECT * FROM USER WHERE
account=13056870 LIMIT 10
怀疑在user 表上是否建立索引:
CREATE TABLE `user` (
`id` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`account` char(11) NOT NULL COMMENT ‘???’,
…………………….
…………………….
PRIMARY KEY (`id`),
UNIQUE KEY `username` (`account`),
…………………….
) ENGINE=InnoDB CHARSET=utf8 ;
查看执行计划,居然查询使用了全表扫描: db@3027 16:55:06>explain
select * from user where account=13056870343;
+—-+————-+——–+——+—————+——+———+——+——+————-+
| id | select_type | table | type | possible_keys | key | key_len | ref |
rows | Extra |
+—-+————-+——–+——+—————+——+———+——+——+————-+
| 1 | SIMPLE | t_user | ALL | username | NULL | NULL | NULL | 799 |
Using where |
+—-+————-+——–+——+—————+——+———+——+——+————-+
1 row in set (0.00 sec)
为什么这里会是全表扫描?account 上不是已经建立索引来吗?仔细一看,
account 定义为了字符串,而传入的条件为数字,我们知道数字的精度是比字符串高的,所以这里做了隐士转换:to_number(account)=13056870343
(to_number 为将字符串转换为数字),这样即使account 上有索引,也没法使用了,因此我们将传入的数字改为字符串:
db@3027 16:55:13>EXPLAIN SELECT * FROM USER WHERE
account='13056870343';
+----+-------------+--------+-------+---------------+----------+------
| id | select_type | TABLE | TYPE | possible_keys | KEY |
key_len | REF | ROWS | Extra |
+----+-------------+--------+-------+---------------+----------+------
| 1 | SIMPLE | t_user | const | username | username | 33
| const | 1 | |
+----+-------------+--------+-------+---------------+----------+------
1 ROW IN SET (0.00 sec)
可以看到数据已经能够索引到索引username 了。
总结:由于用户在设计表结构的时候字段定义使用了字符串,而传入的条件却传入了数字造成了隐士转换,这是数据库应用中经常出现的典型问题; RDS 足够稳定,但不论在怎么强的数据库,也经不起劣质SQL 的挑战,优化sql 是长期的一项优化措施。
从上面的三个案例,我们可以总结一下,用户在使用RDS 的时候,发现数据库执行sql 超时,性能较差,连接超时等等这些问题,大多数情况下,是由于应用程序的设计,sql 没有优化,或者索引建立的不好而导致;除非实例不可用(主机down 掉,实例服务停掉,实例由于空间太大而被锁定)而导致用户应用不可用(实例的故障RDS 会有监控报警)。
文章转载自:http://yun.jinre.com/newsinfo/780258.html
