


前言:
很多站长,当网站数据量非常大的时候,对于整站搜索 ,难免觉得亚历山大,为什么呢?
简单来说你网站有几十条文章,或者几千条文章,还好说一些,如果网站有几千万篇文章呢?搭建自己的搜索引擎, 会不会很头疼?
再加上全文搜索,分词搜索,联想搜索,语义搜索, 这些功能实现起来,真是要费一番周折。还有选取数据库也是一种挑战,创建索引,优化查询语句,整个工序下来,人力物力,工作量确实挺大的!
正文:
说了这么多,就是为了说到 阿里云开放搜索,

先来看一下官方的介绍
开放搜索(OpenSearch)是解决用户结构化数据搜索需求的托管服务,支持数据结构、搜索排序、数据处理自由定制。 开放搜索为您的网站或应用程序提供简单、低成本、稳定、高效的搜索解决方案。
阿里云开放搜索OpenSearch是一款阿里巴巴自主研发的大规模分布式搜索引擎平台,该平台承载了淘宝、天猫、1688、神马搜索、口碑、菜鸟等搜索业务,通过OpenSearch云服务的方式,将阿里巴巴成熟的搜索技术共享给广大开发者。
搜索应用自由创建,动态修改将应用结构简单化、定制化,用户可以通过可视化界面,自由配置文档的字段及属性
多种接入方式,数据自动同步支持RDS、ODPS数据源无缝接入、API/SDK数据上传、界面上传等多种接入方式,数据自动同步和定时索引重建,省时省力!
支持多表,插件式数据处理通过简单操作即可完成多表join和数据处理,数据复杂应用再也不用担心享受不到开放的便捷了!
搜索结果可定制支持两轮相关性排序定制,简单、灵活,加速产品效果迭代。
丰富的搜索结果调优功能设置,提升用户搜索体验拥有查询智能识别,自动提示,超强纠错、模糊搜索、拼音搜索等丰富产品功能
O2O应用已经涉及多个方面,如外卖、电影、旅行等,这类产品对搜索依赖比较重,除了显式用户搜索关键词外,还会根据业务场景根据搜索形成推荐页,有效做到千人千面的展现效果。主要搜索功能有关键词搜索、附近人、配送范围、营业时间、按距离排序、商家打散等。
配合阿里云RDS数据库或者ODPS数据源可以一键同步,步骤简直简单到爆!一个字 那就是爽
那么今天就来跟大家分享一下接入方法:
首先先去开通开放搜索:
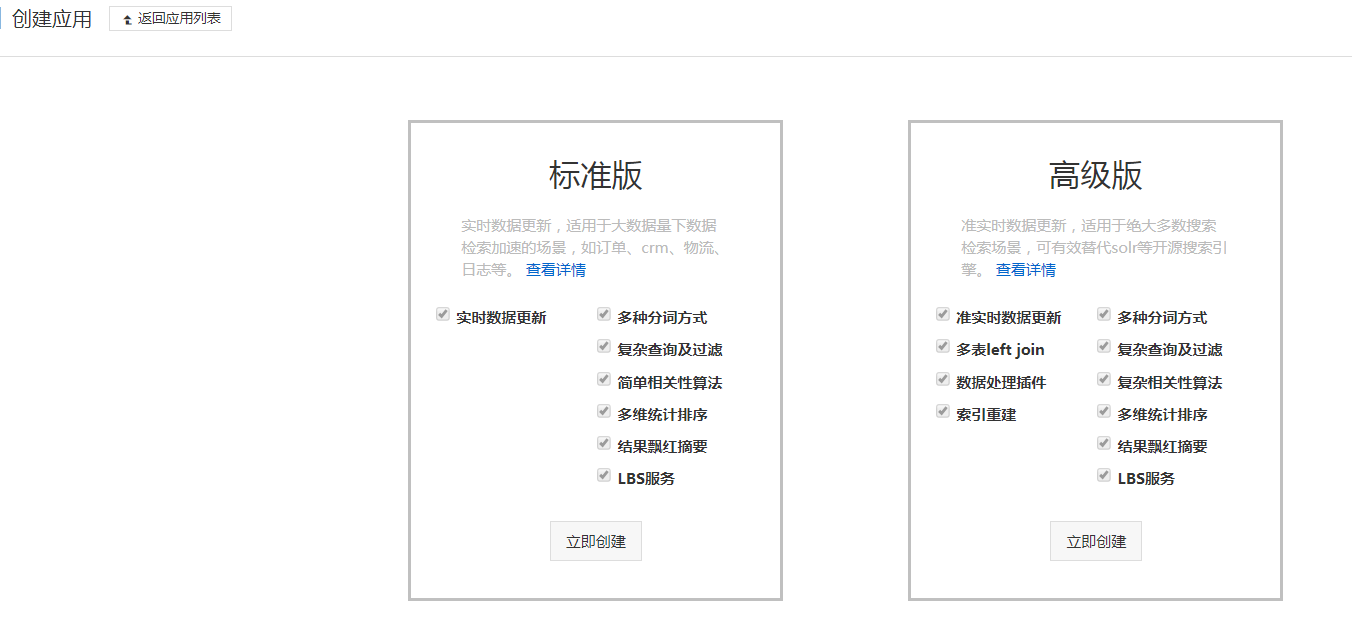
如果前期只是测试, 建议你先使用标准版的入门型,价格比较便宜。一天也就2毛钱左右!
然后创建数据表:

创建索引:

然后就是导入测试数据了, 这里可以整理成json文件,本地上传.不过文件需要分隔,一次最大只能上传2M,每次最多上传1000条数据。那么100万数据 需要分1000次上传.上传python脚本如下:
#! /usr/bin/env python
#coding=utf-8
#json生成
#by http://tools.bugscaner.com/
import json
import md5,time,random,hmac,base64, copy
import urllib
from hashlib import sha1
import httplib
import hashlib
class V3Api:
URI_PREFIX = '/v3/openapi/apps/'
OS_PREFIX = 'OPENSEARCH'
VERB = 'POST'
#定义需推送到的应用表名,替换下面内容为数据需推送到应用中某个表名
TABLE_NAME = '换成自己创建的表'
#定义上传数据,将下面待上传数据替换为自己的数据
def __init__(self,body_json):
self.accesskey_id = '换成自己的'
self.accesskey_secret = '换成自己的'
# 下面host地址,替换为访问对应应用api地址,例如华东1区
self.address = 'opensearch-cn-qingdao.aliyuncs.com'
self.appname = 'ceshiyixia'
self.port = 80
self.body_json = body_json
def runPost(self):
query, header = self.buildQuery(app_name = self.appname,
access_key = self.accesskey_id,
secret = self.accesskey_secret,
http_header = {},
http_params = {})
print query
print header
conn = httplib.HTTPConnection(self.address, self.port)
conn.request(self.VERB, url = query, body = self.body_json, headers = header)
response = conn.getresponse()
return response.status, response.getheaders(), response.read()
def buildQuery(self,
app_name = None,
access_key = None,
secret = None,
http_header = {},
http_params = {}):
uri = self.URI_PREFIX
if app_name is not None:
uri += app_name
uri += '/{TABLE_NAME}/actions/bulk'.format(TABLE_NAME=self.TABLE_NAME)
request_header = self.buildRequestHeader(uri = uri,
access_key = access_key,
secret = secret,
http_params = http_params,
http_header = http_header)
return uri , request_header
def buildAuthorization(self, uri, access_key, secret, http_params, request_header):
canonicalized = self.VERB + '\n'\
+ self.__getHeader(request_header, 'Content-MD5', hashlib.md5(self.body_json).hexdigest()) + '\n' \
+ self.__getHeader(request_header, 'Content-Type', '') + '\n' \
+ self.__getHeader(request_header, 'Date', '') + '\n' \
+ self.__canonicalizedHeaders(request_header) \
+ self.__canonicalizedResource(uri, http_params)
h = hmac.new(secret, canonicalized, sha1)
signature = base64.encodestring(h.digest()).strip()
return '%s %s%s%s' %(self.OS_PREFIX, access_key, ':', signature)
def __getHeader(self, header, key, default_value = None):
if key in header and header[key] is not None:
return header[key]
return default_value
def __canonicalizedHeaders(self, request_header):
header = {}
for key, value in request_header.iteritems():
if key is None or value is None:
continue
k = key.strip(' \t')
v = value.strip(' \t')
if k.startswith('X-Opensearch-') and len(v) > 0:
header[k] = v
if len(header) == 0:
return ''
sorted_header = sorted(header.items(), key=lambda header: header[0])
canonicalized = ''
for (key, value) in sorted_header:
canonicalized += (key.lower() + ':' + value + '\n')
return canonicalized
def __canonicalizedResource(self, uri, http_params):
canonicalized = urllib.quote(uri).replace('%2F', '/')
sorted_params = sorted(http_params.items(), key = lambda http_params : http_params[0])
params = []
for (key, value) in sorted_params:
if value is None or len(value) == 0:
continue
params.append(urllib.quote(key) + '=' + urllib.quote(value))
return canonicalized + '&'.join(params)
def generateDate(self, format = "%Y-%m-%dT%H:%M:%SZ", timestamp = None):
if timestamp is None:
return time.strftime(format, time.gmtime())
else:
return time.strftime(format, timestamp)
def generateNonce(self):
return str(int(time.time()*100)) + str(random.randint(1000, 9999))
def buildRequestHeader(self, uri, access_key, secret, http_params, http_header):
request_header = copy.deepcopy(http_header)
if 'Content-MD5' not in request_header:
request_header['Content-MD5'] = hashlib.md5(self.body_json).hexdigest()
if 'Content-Type' not in request_header:
request_header['Content-Type'] = 'application/json'
if 'Date' not in request_header:
request_header['Date'] = self.generateDate()
if 'X-Opensearch-Nonce' not in request_header:
request_header['X-Opensearch-Nonce'] = self.generateNonce()
if 'Authorization' not in request_header:
request_header['Authorization'] = self.buildAuthorization(uri,
access_key,
secret,
http_params,
request_header)
key_del = []
for key, value in request_header.iteritems():
if value is None:
key_del.append(key)
for key in key_del:
del request_header[key]
return request_header
goods = []
nb = 0
for x in open("updata.txt","r"):
if nb>999:
#这里执行上传然后清空nb
insertdata = json.dumps(goods)
api = V3Api(insertdata)
print api.runPost()
nb = 0
goods = []
else:
infos = {}
fields = {}
oks = x.strip().split(" ")
fields["id"]=oks[0]
fields["title"] = oks[1]
fields["user"] = oks[2]
fields["time"] = oks[4]
fields["size"] = oks[3]
fields["read"] = oks[5]
fields["path"] = "a"
infos["fields"] = fields
infos["cmd"] = "ADD"
goods.append(infos)
nb+=1
updata.txt文件里放入你要导入的文本,一排一行格式如下:

由于本人比较擅长用django开发网站, 所以今天自然要跟大家分享一段接入网站程序的python sdk
官方很早之前写过一个相当简陋的sdk,找了好久才找到。注意这个sdk只是搜索数据库sdk,上面那个python脚本是上传sdk 。
#! /usr/bin/env python
#coding=utf-8
import urllib
import requests
import collections
from hashlib import sha1
import md5,time,random,hmac,base64, copy
class V3Api:
#定义变量
URI_PREFIX = '/v3/openapi/apps/'
OS_PREFIX = 'OPENSEARCH'
def __init__(self, address = '', port = ''):
self.address = address
self.port = port
def runQuery(self,
app_name = None,
access_key = None,
secret = None,
http_header = {},
http_params = {}):
query, header = self.buildQuery(app_name = app_name,
access_key = access_key,
secret = secret,
http_header = http_header,
http_params = http_params)
makeurl = "http://"+self.address+":"+self.port+query
returnjson = requests.get(makeurl,headers=header).json()
return returnjson
#return response.status, response.getheaders(), response.read()
def buildQuery(self,
app_name = None,
access_key = None,
secret = None,
http_header = {},
http_params = {}):
uri = self.URI_PREFIX
if app_name is not None:
uri += app_name
uri += '/search'
param = []
for key, value in http_params.iteritems():
param.append(urllib.quote(key) + '=' + urllib.quote(value))
query = ('&'.join(param))
request_header = self.buildRequestHeader(uri = uri,
access_key = access_key,
secret = secret,
http_params = http_params,
http_header = http_header)
return uri + '?' + query, request_header
# 签名实现
def buildAuthorization(self, uri, access_key, secret, http_params, request_header):
canonicalized = 'GET\n'\
+ self.__getHeader(request_header, 'Content-MD5', '') + '\n' \
+ self.__getHeader(request_header, 'Content-Type', '') + '\n' \
+ self.__getHeader(request_header, 'Date', '') + '\n' \
+ self.__canonicalizedHeaders(request_header) \
+ self.__canonicalizedResource(uri, http_params)
h = hmac.new(secret, canonicalized, sha1)
signature = base64.encodestring(h.digest()).strip()
return '%s %s%s%s' %(self.OS_PREFIX, access_key, ':', signature)
def __getHeader(self, header, key, default_value = None):
if key in header and header[key] is not None:
return header[key]
return default_value
def __canonicalizedResource(self, uri, http_params):
canonicalized = urllib.quote(uri).replace('%2F', '/')
sorted_params = sorted(http_params.items(), key = lambda http_params : http_params[0])
params = []
for (key, value) in sorted_params:
if value is None or len(value) == 0:
continue
params.append(urllib.quote(key) + '=' + urllib.quote(value))
return canonicalized + '?' + '&'.join(params)
def generateDate(self, format = "%Y-%m-%dT%H:%M:%SZ", timestamp = None):
if timestamp is None:
return time.strftime(format, time.gmtime())
else:
return time.strftime(format, timestamp)
def generateNonce(self):
return str(int(time.time()*100)) + str(random.randint(1000, 9999))
def __canonicalizedHeaders(self, request_header):
header = {}
for key, value in request_header.iteritems():
if key is None or value is None:
continue
k = key.strip(' \t')
v = value.strip(' \t')
if k.startswith('X-Opensearch-') and len(v) > 0:
header[k] = v
if len(header) == 0:
return ''
sorted_header = sorted(header.items(), key=lambda header: header[0])
canonicalized = ''
for (key, value) in sorted_header:
canonicalized += (key.lower() + ':' + value + '\n')
return canonicalized
# 构建请求 Header 参数
def buildRequestHeader(self, uri, access_key, secret, http_params, http_header):
request_header = copy.deepcopy(http_header)
if 'Content-Type' not in request_header:
request_header['Content-Type'] = 'application/json'
if 'Date' not in request_header:
request_header['Date'] = self.generateDate()
if 'X-Opensearch-Nonce' not in request_header:
request_header['X-Opensearch-Nonce'] = self.generateNonce()
if 'Authorization' not in request_header:
request_header['Authorization'] = self.buildAuthorization(uri,
access_key,
secret,
http_params,
request_header)
key_del = []
for key, value in request_header.iteritems():
if value is None:
key_del.append(key)
for key in key_del:
del request_header[key]
return request_header
def sqlquery(query_subsentences_params):
accesskey_id = '改成自己的'
accesskey_secret = '改成自己的'
# 下面的值替换为应用访问api地址,例如 opensearch-cn-hangzhou.console.aliyun.com
internet_host = 'opensearch-cn-qingdao.aliyuncs.com'
appname = 'ceshiyixia'
api = V3Api(address = internet_host, port = '80')
return api.runQuery(app_name = appname, access_key=accesskey_id, secret=accesskey_secret, http_params=query_subsentences_params, http_header={})
if __name__ == '__main__':
accesskey_id = '改成自己的'
accesskey_secret = '改成自己的'
# 下面的值替换为应用访问api地址,例如 opensearch-cn-hangzhou.console.aliyun.com
internet_host = 'opensearch-cn-qingdao.aliyuncs.com'
appname = 'ceshiyixia'
api = V3Api(address = internet_host, port = '80')
# 下面为设置查询信息,query参数中可设置对应的查询子句,添加查询参数,参考fetch_fields用法
#'query': "query=name:'搜索'&&config=start:0,hit:1,format:json&&sort=+id", 这句是官方语句
#start:0,hit:1 这两个好像是分页
query_subsentences_params = {
'query': "query=title:'搜索'&&config=start:0,hit:1,format:json",
'fetch_fields':'id;title'
}
print api.runQuery(app_name = appname, access_key=accesskey_id, secret=accesskey_secret, http_params=query_subsentences_params, http_header={})
导入模块接入到自己的django视图函数里即可:
大概关键代码如下:
searchdict = {
'query': "query=title:'"+keyword+"'&&config=start:"+str((page-1)*10)+",hit:10,format:fulljson",
'fetch_fields':'id;title;user;size;read;time;path',
'summary':'''summary_field:title,summary_element:em,summary_snipped:2''',
}
jieguo = sqlquery(searchdict)
好了文章导入完成后测试一下搜索:
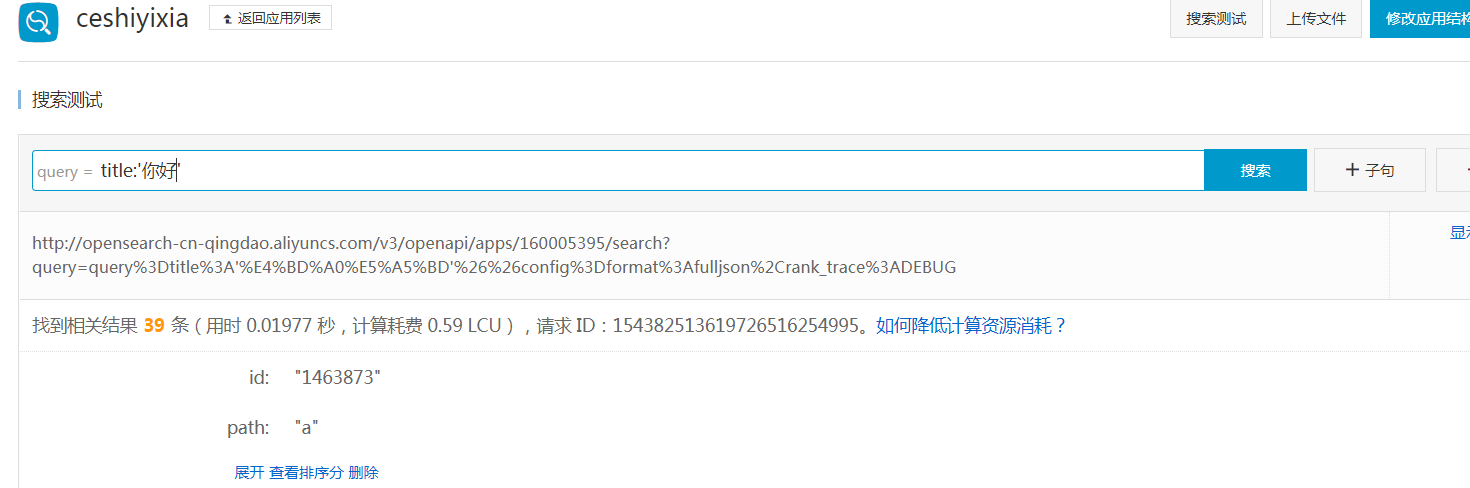
导入了测试数据大概5万条, 查询速度相当快 ,l来看一下接入sdk在django查询中的效果:

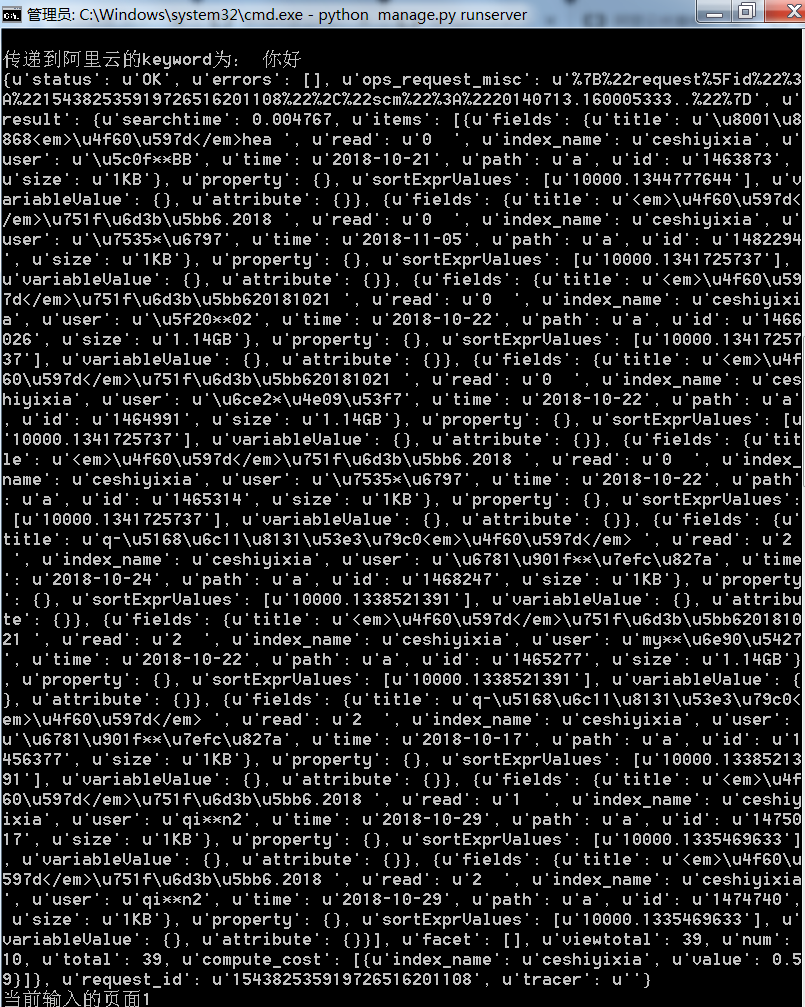
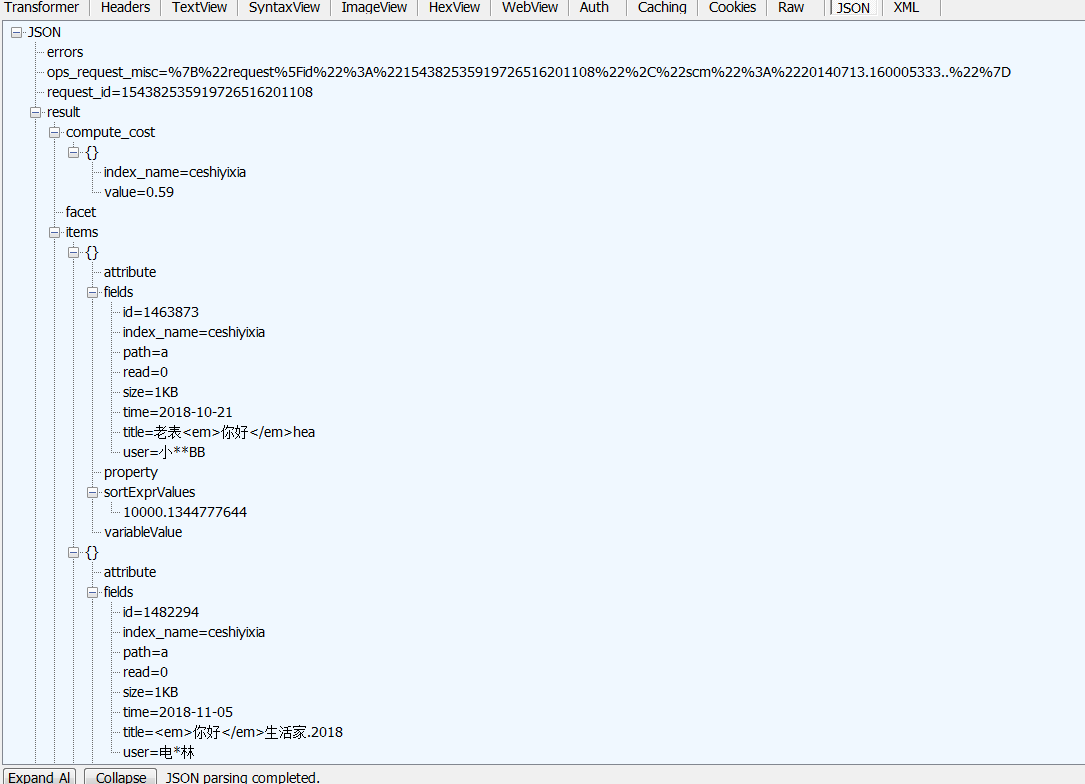
完全正常!bye
#文中提到的产品前往连接地址:
